How to save the contents of a PDF to a text file.(Power Automate Desktop)
Learn how to extract text in a PDF file and save it to a text file.
For text information
Overall flow
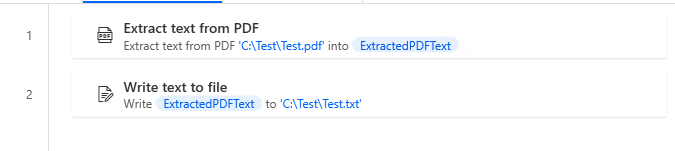
Robin(for copy and paste)
It can be copied and pasted into Power Automate Desktop.
Pdf.ExtractTextFromPDF.ExtractText PDFFile: $'''C:\\Test\\Test.pdf''' DetectLayout: False ExtractedText=> ExtractedPDFText File.WriteText File: $'''C:\\Test\\Test.txt''' TextToWrite: ExtractedPDFText AppendNewLine: True IfFileExists: File.IfFileExists.Overwrite Encoding: File.FileEncoding.Unicode
Steps
First, put "Extract text from PDF" in place and specify the target PDF.
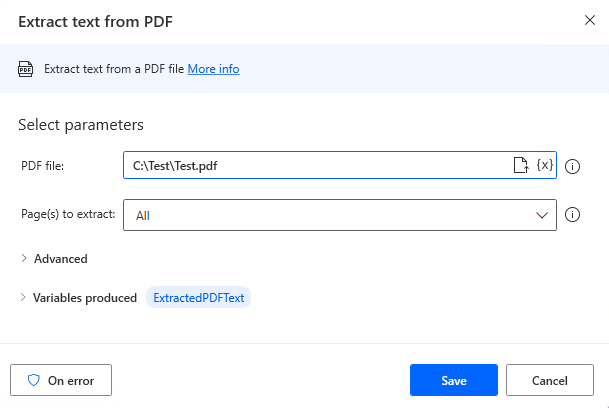
Then put in place "Write text to file" and you are done.
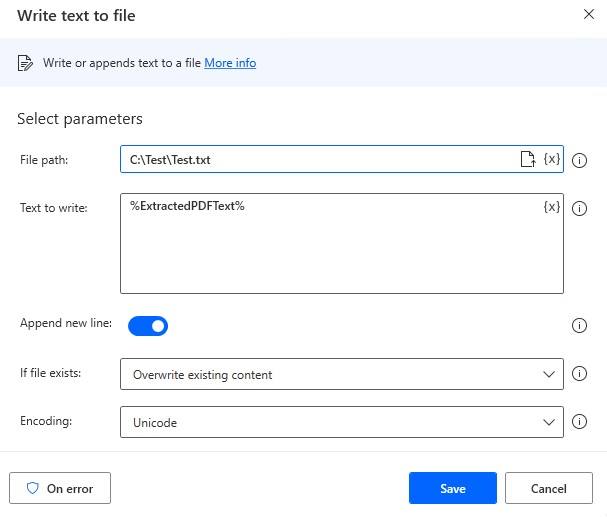
Specify %ExtractedPDFText% for "Text to write" parameter.
(if you have not renamed the variable produced)
For extract text information from an image
Overall flow
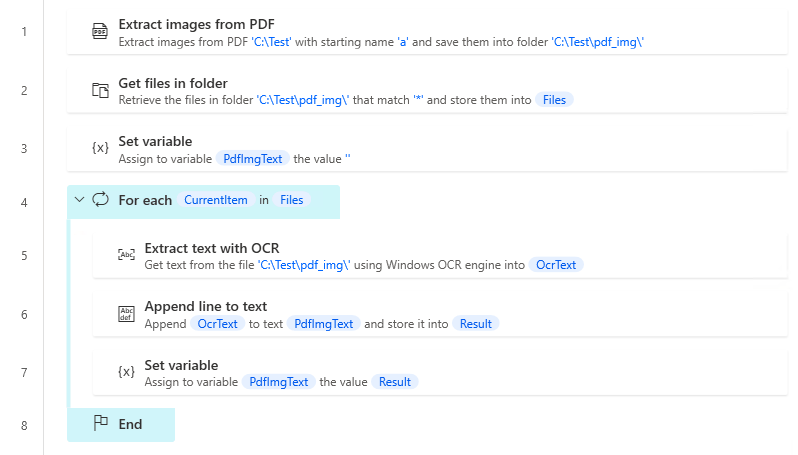
Robin(for copy and paste)
It can be copied and pasted into Power Automate Desktop.
Pdf.ExtractImagesFromPDF.ExtractImages PDFFile: $'''C:\\Test''' ImagesName: $'''a''' ImagesFolder: $'''C:\\Test\\pdf_img\\'''
Folder.GetFiles Folder: $'''C:\\Test\\pdf_img\\''' FileFilter: $'''*''' IncludeSubfolders: False FailOnAccessDenied: True SortBy1: Folder.SortBy.NoSort SortDescending1: False SortBy2: Folder.SortBy.NoSort SortDescending2: False SortBy3: Folder.SortBy.NoSort SortDescending3: False Files=> Files
SET PdfImgText TO $'''%''%'''
LOOP FOREACH CurrentItem IN Files
OCR.ExtractTextWithOCR.ExtractTextFromFileWithWindowsOcr ImageFile: $'''C:\\Test\\pdf_img\\''' WindowsOcrLanguage: OCR.WindowsOcrLanguage.English ImageWidthMultiplier: 1 ImageHeightMultiplier: 1 OcrText=> OcrText
Text.AppendLine Text: PdfImgText LineToAppend: OcrText Result=> Result
SET PdfImgText TO Result
END
Steps
Text information can be extracted from images to some extent.
However, it may not be read properly due to OCR.
Also, since text and images are extracted separately, the text and images cannot be read in the same order.
To create a flow, first put "Extract images from PDF" in place.
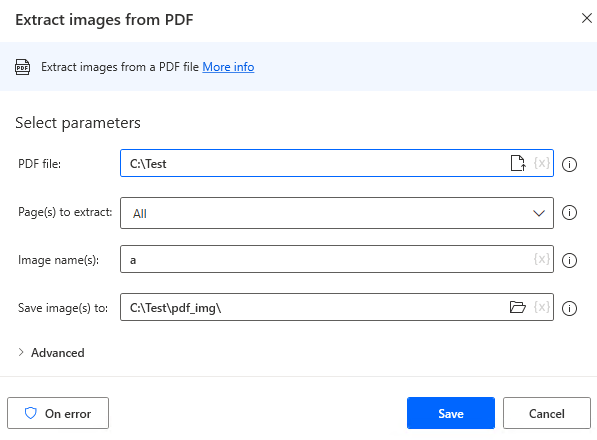
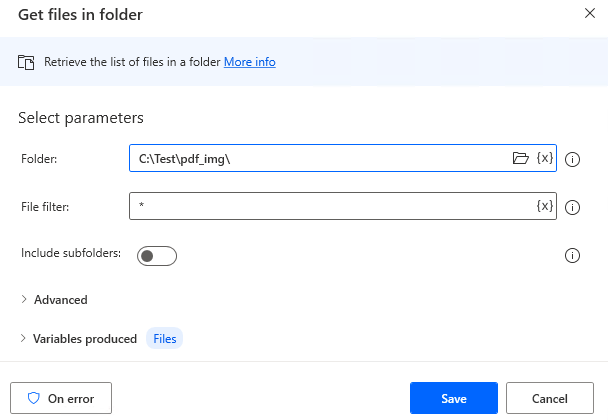
Next, put in place the "Get files in folder".
Specify the destination folder for "Extract images from PDF".
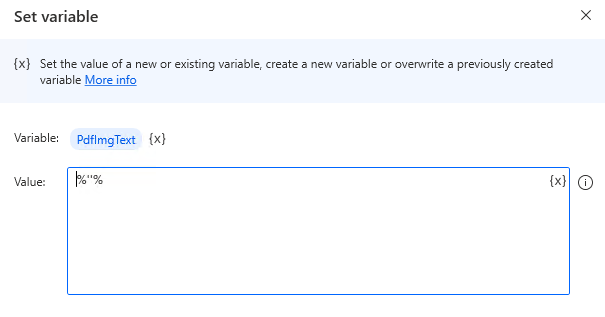
Next, Create the variable %PdfImgText%.
Specify %''% for the "Value" parameter.
Next, put in place "For each" and specify in the "Value to iterate" parameter the variable produced by "Get files in folder", %Files%.
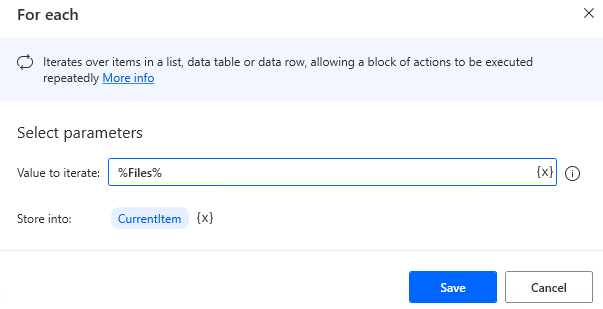
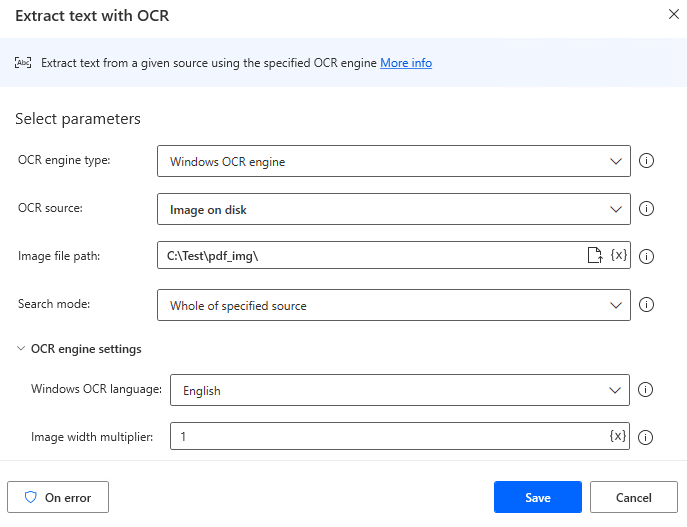
Next, put "Extract text with OCR" in "For each".
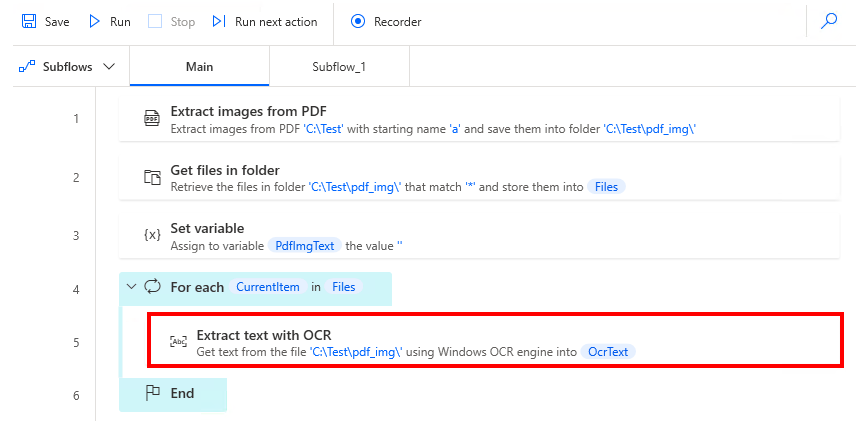
| Parameter | Value |
|---|---|
| OCR engine type | Windows OCR engine |
| OCR source | Image on disk |
| Image file path | Destination folder for "Extract images from PDF". |
| Search mode | Whole of specified source |
| Windows OCR language | Select the language of the image. |
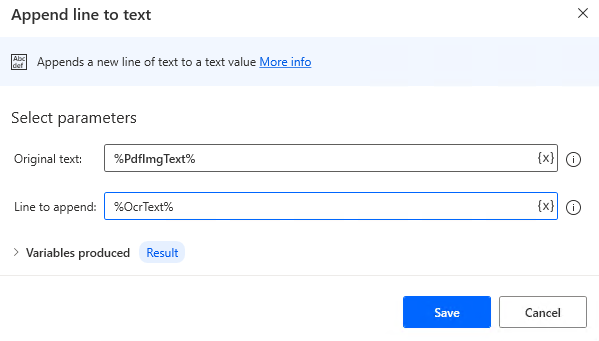
Next, put "Append line to text" in "For each".
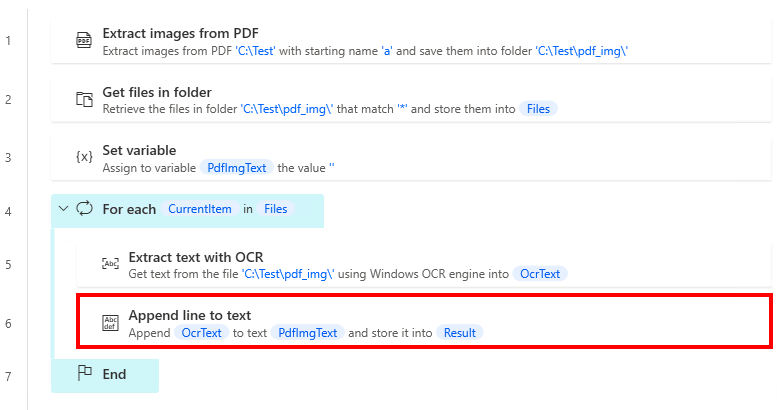
| Parameter | Value |
|---|---|
| Original text | %PdfImgText% |
| Line to append | %OcrText% |
Finally, put "Set Variables" in "For each".
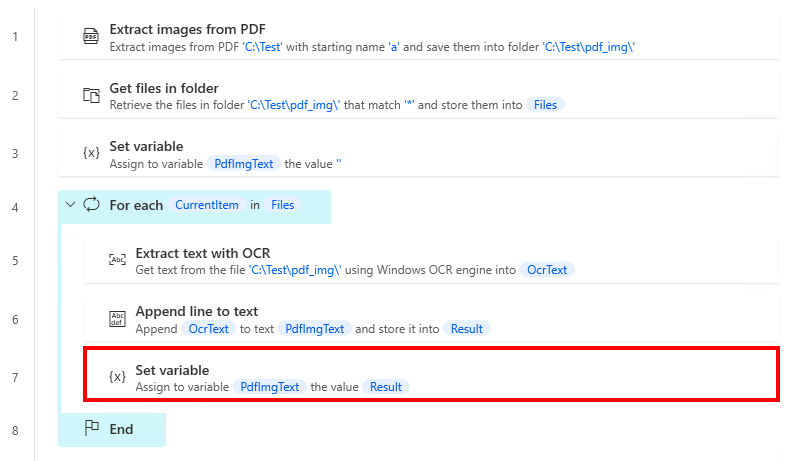
| Parameter | Value |
|---|---|
| Variable | %PdfImgText% |
| Value | %Result% |
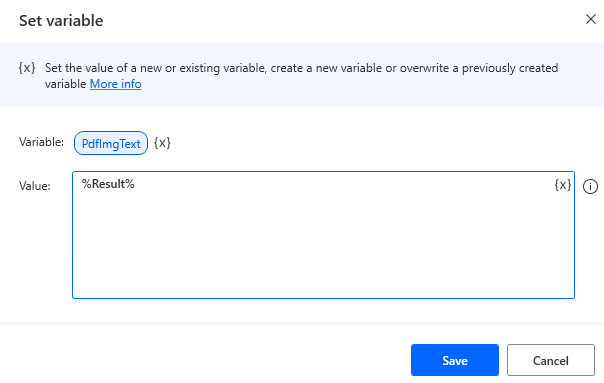
After the flow is complete, the variable %PdfImgText% is set to the result of reading and combining all images.
For those who want to learn Power Automate Desktop effectively
The information on this site is now available in an easy-to-read e-book format.
Or Kindle Unlimited (unlimited reading).

You willl discover how to about basic operations.
By the end of this book, you will be equipped with the knowledge you need to use Power Automate Desktop to streamline your workflow.