Extract text from PDF Action(Power Automate Desktop)
This action extracts text information contained in the PDF and stores it in a variable.
Text that is represented by an image cannot be retrieved.
How to use
Drag "Extract text from PDF" under "PDF".
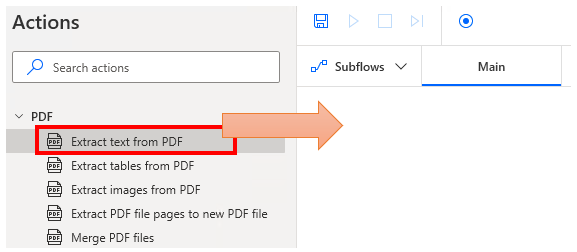
Set parameters.
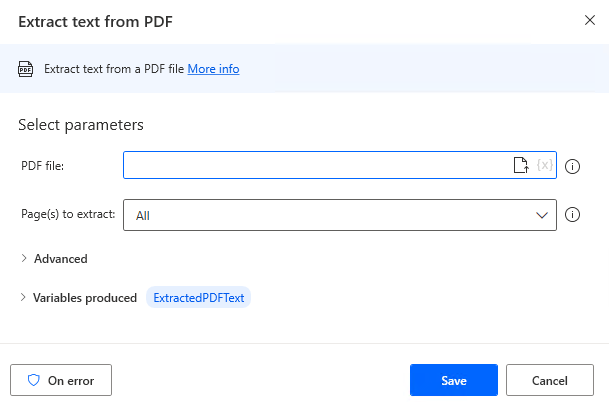
Parameter
PDF File
Specifies the target PDF file.

Page(s) to extract
Specify the pages to search.
For single or range, specify additional number of pages.
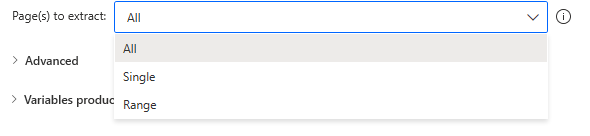
All
All pages are covered.
No parameters to be added.

Single
Specify one target page with the additional parameter "Single page number".

Range
Specify the target page range with the additional parameters "From page number" and "To page number".

Password
Specify if a password is required to open the PDF file.
Leave empty to open without password.

Optimized for structured data
When ON, it will try to reproduce margins with spaces.
You may want to test with ON and OFF to determine how they are taken in.

Variables produced
ExtractedPDFText
Contains text extracted from the PDF.
For those who want to learn Power Automate Desktop effectively
The information on this site is now available in an easy-to-read e-book format.
Or Kindle Unlimited (unlimited reading).

You willl discover how to about basic operations.
By the end of this book, you will be equipped with the knowledge you need to use Power Automate Desktop to streamline your workflow.